


Es hat sich vielgetan im letzten Jahr, deshalb gab es jetzt ein riesengroßes Update dieses Artikels:
05.08.2025
Hast du dich jemals mitten in einer Konversation mit ChatGPT gefragt, warum das Modell plötzlich vergisst, was du gerade gesagt hast? Dieses Phänomen kann nicht nur nervenaufreibend sein, sondern auch deinen Workflow erheblich stören. Stell dir vor, du bist gerade dabei, einen komplexen Social-Media-Post zu formulieren oder eine SEO-Analyse durchzuführen, und plötzlich verliert ChatGPT den Faden. Es ist, als würde die Welt sich in Zeitlupe um dich herum drehen, während du versuchst, alle Informationen im Kopf zu behalten.
Aber keine Sorge, das ist kein „Bug“ im herkömmlichen Sinne, sondern eine fundamentale Eigenschaft, wie diese beeindruckenden KI-Modelle funktionieren. Dieser Bericht taucht tief ein, um zu verstehen, warum das passiert, vergleicht, wie verschiedene KIs damit umgehen, und – das Wichtigste – zeigt auf, wie man selbst die Gespräche mit der KI optimieren kann, um kohärentere und produktivere Ergebnisse zu erzielen.
In diesem Artikel gehen wir dem Geheimnis der „Tokens“ auf den Grund und zeigen dir zwei effektive Lösungen, um dieses nervige Problem zu umgehen.
Was sind Kontextfenster und Tokens?
Was ist das Kontextfenster?
Wenn man mit einem großen Sprachmodell (LLM) wie ChatGPT interagiert, spricht man nicht mit einem allwissenden Geist. Man kommuniziert mit einem System, das eine sehr reale „Erinnerungsgrenze“ besitzt. Diese Grenze wird als Kontextfenster bezeichnet. Es ist vergleichbar mit einer Box, die festlegt, wie viel das Modell gleichzeitig „erinnern“ und verarbeiten kann.
Man kann sich das wie einen kleinen Notizblock vorstellen, den die KI bei sich trägt. Darauf kann sie sich wichtige Punkte aus einem Gespräch notieren, aber der Block hat nur wenige Seiten. Wenn das Gespräch kurz ist, passt alles darauf. Wird es länger, muss die KI alte Notizen radieren, um Platz für neue zu schaffen. Sobald der Notizblock voll ist, kann das Modell die älteren Teile nicht mehr „sehen“ und beginnt, sich auf Vermutungen statt auf tatsächliche Erinnerung zu verlassen. Dieses Kontextfenster ist die maximale Textmenge, die das Modell in einer einzigen Eingabe verarbeiten kann. Es ist entscheidend, denn es beeinflusst direkt die Fähigkeit des LLM, Text basierend auf dem gegebenen Kontext zu verstehen und zu generieren.
Die anfängliche Wahrnehmung, dass ChatGPT wie ein Mensch „vergisst“, ist eine Trugbild. LLMs besitzen kein echtes Gedächtnis und sind grundlegend „zustandslos“ (engl. „stateless“). Sie speichern nicht, was man gesagt hat, oder rufen es später auf menschliche Weise ab. Jede Interaktion wird als eine neue Anfrage behandelt. Die wahrgenommene „Erinnerung“ ist lediglich die Konversationshistorie, die bei jeder Runde
erneut zusammen mit der neuen Eingabe in das Modell eingespeist wird. Dies führt zu einer „Illusion von Erinnerung“. Das „Vergessen“ ist somit eine direkte Konsequenz dieser Zustandslosigkeit und des festen Kontextfensters, nicht ein Fehler im Gedächtnis des Modells.
Grundlagen der Tokens
Ein Token ist die kleinste Einheit, die ein Modell wie ChatGPT versteht. Es kann ein Wort, ein Teil eines Wortes oder sogar nur ein Zeichen sein. ChatGPT und andere große Sprachmodelle zerlegen die Wörter, die wir eingeben, in diese Tokens, um sie zu verstehen und darauf zu reagieren.
Warum Tokens wichtig sind
Tokens sind nicht nur die Bausteine der Konversation, sondern auch der Schlüssel zum Verständnis, warum ChatGPT manchmal den Anfang der Konversation vergisst. Jedes Modell hat eine maximale Token-Grenze. Bei ChatGPT 4, lag diese Grenze bei etwa 8.000 Tokens. Sobald diese Grenze erreicht ist, beginnt das Modell, ältere Tokens zu vergessen, um Platz für neue zu schaffen. Wenn du, wie ich es bisher empfohlen habe, versuchst, mehrere Aufgaben in einem einzigen Chat zu erledigen, kannst du schnell an die Token-Grenze stoßen. Das führt dazu, dass ChatGPT den Anfang der Konversation vergisst. Es ist, als würde die Welt sich in Zeitlupe um dich herum drehen, während du versuchst, alle Informationen im Kopf zu behalten. Das ist besonders problematisch, wenn der Anfang der Konversation wichtige Kontextinformationen enthält, die für das Verständnis der gesamten Unterhaltung entscheidend sind.
Ein Beispiel: Ich hatte eine lange Übersetzungsarbeit und habe ChatGPT zu Beginn mit allen notwendigen Anweisungen gefüttert. Irgendwann hat es aber dann einfache Anweisungen, wie „Bleibe per DU“ vergessen. Ich musste also einen neuen Chat öffnen.
Wenn ein Gespräch zu lang wird und das Kontextfenster überschreitet, werden die älteren Teile „abgeschnitten“ oder einfach verworfen. Dies ist kein Fehler, sondern eine inhärente Einschränkung der zugrundeliegenden Architektur. Dieses Phänomen wird als „Context Degradation Syndrome“ (CDS) bezeichnet und führt zu Lücken, Inkonsistenzen und dem Gefühl, dass die KI „den Faden verliert“. Dabei wird nicht zwischen unwichtigen und kritischen Kontexten unterschieden; beides wird gelöscht. Man kann sich das vorstellen, als würde man ein detailliertes Gespräch mit jemandem führen, nur um festzustellen, dass diese Person alles vergisst, was man früher gesagt hat, sobald eine bestimmte Wortgrenze erreicht ist – das kann verwirrend und frustrierend sein.
Wenn Gespräche länger werden, können sich kleine Fehlinterpretationen oder irrelevante Details im Laufe der Zeit verstärken. Jede Antwort baut auf der vorherigen auf, was bedeutet, dass selbst geringfügige Missverständnisse am Anfang zu größeren Problemen führen können. Dieser „Schneeballeffekt“ kann dazu führen, dass Antworten zunehmend unzusammenhängend oder irrelevant wirken.
Das „Context Degradation Syndrome“
Das Design von LLMs, insbesondere der Self-Attention-Mechanismus, macht die Verarbeitung längerer Kontexte exponentiell teurer. Diese rechnerische Einschränkung ist der grundlegende Grund für die Begrenzung des Kontextfensters, und nicht etwa ein Mangel an „Intelligenz“ oder „Gedächtnis“ im menschlichen Sinne. Dieser Kompromiss zwischen Leistung, Kosten und Kontextlänge ist eine zentrale Herausforderung im LLM-Design. Die Zustandslosigkeit und das feste Kontextfenster sind keine willkürlichen Einschränkungen, sondern grundlegende Designentscheidungen, die in der Transformer-Architektur verwurzelt sind. Die Alternative, ein echtes, persistentes Gedächtnis, wäre für aktuelle LLMs rechnerisch unerschwinglich. Dies verdeutlicht einen Kernkompromiss: Aktuelle LLMs priorisieren die Effizienz für die Einzelverarbeitung gegenüber einem komplexen, menschenähnlichen Langzeitgedächtnis. Das „Vergessen“ ist eine direkte Folge dieser technischen Entscheidung, LLMs praktisch und skalierbar zu machen.
Kontextfenster-Größen beliebter LLMs (Stand 2025)
Um die Fähigkeiten verschiedener Modelle besser einordnen zu können, bietet die folgende Tabelle einen Überblick über die Kontextfenster-Größen einiger beliebter LLMs. Die Zahlen zeigen die rasante Entwicklung in diesem Bereich auf, von frühen Modellen mit wenigen tausend Tokens bis hin zu heutigen Schwergewichten, die Hunderttausende oder sogar Millionen verarbeiten können.
| Modell (Anbieter) | Kontextfenster (Tokens) | Max. Ausgabe (Tokens) | Wissensstand (Cutoff) | Anmerkungen |
| GPT-2 (OpenAI) | ~2.000 | N/A | Älter | Frühes Modell, zum Vergleich der Entwicklung. |
| GPT-3 (OpenAI) | 2.049 | N/A | Älter | Initialversion. |
| ChatGPT 3.5 Turbo (OpenAI) | 16.385 | 4.096 | Sep. 2021 | Schnell und kostengünstig. |
| GPT-4 (OpenAI) | 8.192 / 32.768 | N/A | N/A | Initialversionen. |
| GPT-4 Turbo (OpenAI) | 128.000 | 4.096 | Dez. 2023 | Verbesserte Version von GPT-4. |
| ChatGPT Plus (OpenAI, Chat-UI) | 32.000 | N/A | N/A | Für Plus-Abonnenten in der Chat-Oberfläche. |
| OpenAI GPT-4.1 (API) | 1.047.576 | 32.768 | Mai 2024 | Nur über API verfügbar, nicht in ChatGPT UI. |
| ChatGPT 4o (OpenAI) | 128.000 | 16.384 | Okt. 2023 | „Omni“-Modell, multimodal (Text, Bild, Audio). |
| ChatGPT 4o mini (OpenAI) | 128.000 | 16.384 | Okt. 2023 | Kleinere, schnellere und kostengünstigere Version von 4o. |
| OpenAI o1-preview (API) | 128.000 | 32.000 | Okt. 2023 | |
| OpenAI o1-mini (API) | 128.000 | 64.000 | Okt. 2023 | |
| OpenAI o3 / o3-mini (API) | 128.000 | 48.000 / 32.000 | Dez. 2024 | Reasoning-fokussiert, spezialisiert auf STEM. |
| Claude 2 (Anthropic) | 100.000 | N/A | N/A | |
| Claude 3 Opus (Anthropic) | 200.000 | N/A | N/A | Erweiterung auf 1 Mio. Tokens für spezielle Fälle. |
| Gemini 1.0 (Google) | 32.000 | N/A | N/A | |
| Gemini 1.5 Pro (Google) | 128.000 Standard / bis zu 1 Mio. für Tester / 2 Mio. | N/A | N/A | Unterstützt bis zu 19 Std. Audio mit 2 Mio. Tokens. |
| Llama 2 (Meta) | 4.000 | N/A | N/A | Open-Source-Modell. |
| Llama 3 (Meta) | 8.000 | N/A | N/A | Open-Source-Modell, doppelt so groß wie Llama 2. |
| Llama 3.1 (Meta) | 128.000 | N/A | N/A | Open-Source-Modell, deutliche Erweiterung. |
| Mistral Small 3.1 (Mistral AI) | 128.000 | N/A | N/A | |
| Mistral Large 2 (Mistral AI) | 128.000 | N/A | N/A | Für Single-Node-Inferenz mit langen Kontexten. |
Die Herausforderungen großer Kontextfenster: Mehr ist nicht immer besser
Quadratische Kosten und Langsamkeit
Während größere Kontextfenster auf den ersten Blick fantastisch erscheinen, bringen sie auch erhebliche Nachteile mit sich. Die benötigte Rechenleistung skaliert exponentiell: Eine Verdopplung der Tokens vervierfacht den Rechenaufwand. Das bedeutet langsamere Antwortzeiten, höhere Serverkosten und eine höhere Fehlerrate. Die Verarbeitung riesiger Textmengen ist rechnerisch teuer und langsam. Abfragen mit langem Kontext erhöhen typischerweise die Datenverarbeitungszeiten und erfordern mehr Rechenressourcen, was potenziell zu höheren Kosten führen kann.
Der exponentielle Anstieg der Rechenkosten ist nicht nur ein technisches Detail; er stellt eine grundlegende ökonomische Barriere dar. Selbst mit schnell fortschreitender Hardware werden die Kosten für die Verarbeitung extrem großer Kontexte für jede einzelne Benutzerinteraktion für die Anbieter unerschwinglich. Dies bedeutet, dass, obwohl technisch möglich, größere Kontextfenster in der praktischen Anwendung oft Kompromisse erfordern (wie die 32k-Grenze für ChatGPT Plus-Nutzer im Vergleich zum API-Zugang zu 1M Tokens ). Dies führt zu einem gestuften Zugang zu „Erinnerung“ basierend auf der Zahlungsbereitschaft und verdeutlicht die wirtschaftlichen Realitäten hinter den Fähigkeiten von LLMs.
Das „Nadel im Heuhaufen“-Problem
Eine große Herausforderung bei sehr langen Kontexten ist das sogenannte „Needle in a Haystack“-Problem (Nadel im Heuhaufen). Wenn die Textmenge (der „Heuhaufen“) wächst, kann das Modell Schwierigkeiten haben, ein spezifisches, entscheidendes Detail (die „Nadel“) zu finden. Die Aufmerksamkeit des Modells wird verwässert, was dazu führt, dass es wichtige Fakten übersieht. Ein Beispiel hierfür ist das Übersehen eines kritischen Satzes über einen Projektfehler in einem 200-seitigen Bericht.
Studien zeigen, dass Modelle am besten funktionieren, wenn wichtige Informationen am Anfang oder Ende der Eingabe stehen. Das Vergraben wichtiger Details mitten in einer riesigen Eingabe führt dazu, dass das Modell Schwierigkeiten hat. Dies führt zu einer „U-förmigen“ Leistungskurve, bei der die Erinnerung in der Mitte schlechter ist. Die Leistung nimmt auch ab, wenn die Anzahl der „Nadeln“ (Fakten, die abgerufen werden sollen) zunimmt und wenn das LLM über mehrere abgerufene Fakten nachdenken muss.
Das „Nadel im Heuhaufen“-Problem offenbart einen entscheidenden Unterschied: Ein großes Kontextfenster bietet
Zugang zu Informationen, aber nicht unbedingt eine effektive Verarbeitung oder ein Verständnis all dieser Informationen. Der „Aufmerksamkeitsmechanismus“ , der es LLMs ermöglicht, „den gesamten Input zu betrachten“ , kann in sehr langen Kontexten „diffus“ oder „überlastet“ werden. Dies deutet darauf hin, dass eine bloße Erweiterung der Kontextfenstergröße nicht automatisch zu einem tieferen Verständnis oder einer zuverlässigen Erinnerung führt, insbesondere bei komplexen Denkaufgaben. Es weist auf eine Einschränkung in der Art und Weise hin, wie LLMs Informationen
verarbeiten, nicht nur darauf, wie viel sie sehen können. Das bedeutet, dass die bloße Bereitstellung von mehr Text nicht garantiert, dass die KI ihn optimal nutzt, insbesondere bei Aufgaben, die das Verfolgen mehrerer Variablen oder komplexe Zusammenfassungen erfordern.
Sicherheitsaspekte
Längere Kontexte können auch Sicherheitsrisiken bergen. Bösartige Anweisungen könnten tief in einer langen Eingabe versteckt sein und Sicherheitsfilter umgehen. Je größer das Fenster, desto schwieriger ist es, alles zu erkennen.
Lösungen für das Token-Problem
Token Counter Plugin
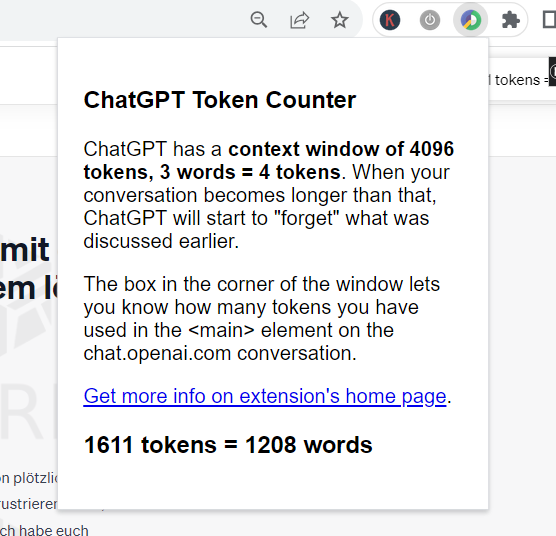
Eine der einfachsten und effektivsten Lösungen ist die Verwendung eines Token Counter Plugins, beispielsweise für den Chrome-Browser. Dieses kleine, aber mächtige Tool zeigt dir in Echtzeit an, wie viele Tokens du in einer Konversation bereits verbraucht hast. So kannst du besser steuern, wann es Zeit ist, einen neuen Chat zu beginnen, und vermeidest das Risiko, wichtige Informationen zu verlieren, wie der Phönix aus der Asche.
Cleveres Prompt Engineering
Da LLMs Informationen am Anfang und Ende des Prompts priorisieren , sollte man die Prompts so strukturieren, dass wichtige Details dort platziert werden. Es ist ratsam, wichtige Informationen zu wiederholen, besonders wenn das Gespräch lang ist oder vom Thema abgewichen ist. Man sollte nicht davon ausgehen, dass die KI sich an alles von vor 20 Runden erinnert. Man sollte spezifisch und prägnant sein und unnötige Weitschweifigkeit vermeiden, die wichtigen Kontext aus dem Fenster drängen könnte.
Text-Häppchen (Chunking) und Kürzen (Truncation)
Wenn man möchte, dass das LLM einen Text verarbeitet, der größer ist als sein Kontextfenster (z.B. ein langes Dokument zusammenfasst), sollte man ihn in kleinere, überschaubare Segmente oder „Chunks“ aufteilen. Man fasst dann jeden Chunk einzeln zusammen und kombiniert anschließend die Zusammenfassungen. Dies ist eine gängige Problemumgehung. Man sollte verstehen, dass bei zu langen Gesprächen die Client-Software oft die älteren Teile „abschneidet“, d.h. sie gehen verloren. So wird der „Schiebefenster“-Effekt in der Praxis erzielt.
Hast du beispielsweise einen langen Chat und ChatGPT beginnt zu vergessen, dann lasse dir den bisherigen Chat zusammenfassen, lade dir diese Zusammenfassung als TXT-Datei runter, öffne einen neuen Chat und briefe diesen neuen Chat mit dieser Zusammenfassung!
Das „Schiebefenster“-Prinzip
Konversationsschnittstellen für LLMs verwenden oft ein „Schiebefenster“ des jüngsten Textes, um Antworten zu generieren. Das bedeutet, dass mit jeder neuen Nachricht die ältesten Nachrichten aus dem Fenster fallen, um Platz zu schaffen. Dies stellt sicher, dass das Modell immer den aktuellsten Kontext hat, auch wenn es den Anfang eines sehr langen Chats „vergisst“.
Die Zukunft der KI-Erinnerung: Was Entwickler tun
Retrieval-Augmented Generation (RAG): Die externe Bibliothek der KI
Was es ist: RAG ist ein KI-Framework, das LLMs mit traditionellen Informationsabrufsystemen (wie Suchmaschinen oder Datenbanken) kombiniert. Es ist im Wesentlichen so, als würde man dem LLM eine externe, ständig aktualisierte „Bibliothek“ zur Verfügung stellen, die es konsultieren kann.
Mechanismus (Analogie: Die smarte Bibliothekarin):
- Indizierung (Bücher katalogisieren): Zuerst werden externe Daten (Dokumente, Webseiten, Wissensdatenbanken) verarbeitet und in numerische Darstellungen, sogenannte „Embeddings“, umgewandelt und in einer „Vektordatenbank“ gespeichert. Man kann sich das vorstellen wie eine Bibliothekarin, die jedes Buch in der Bibliothek akribisch katalogisiert und dessen Inhalt und Schlüsselwörter notiert, damit es schnell gefunden werden kann.
- Abruf (Recherche): Wenn man dem LLM eine Frage stellt, sucht ein „Dokumenten-Retriever“ in dieser Vektordatenbank nach den relevantesten Informationen. Die Bibliothekarin findet schnell die relevantesten Bücher oder Artikel zu der Anfrage.
- Generierung (Antwort formulieren): Nur diese hochrelevanten Schnipsel werden dann dem ursprünglichen Prompt hinzugefügt und dem LLM zugeführt. Das LLM verwendet diesen „erweiterten“ Prompt, um eine Antwort zu generieren, wobei es sein vortrainiertes Wissen mit den frischen, abgerufenen Informationen verbindet. Die Bibliothekarin reicht der KI die relevanten Bücher, die diese dann verwendet, um eine präzise Antwort zu formulieren.
Vorteile:
- Zugang zu aktuellen Informationen: LLMs sind durch den Stichtag ihrer Trainingsdaten begrenzt. RAG überwindet dies, indem es aktuelle Informationen bereitstellt.
- Faktische Fundierung & Reduzierung von Halluzinationen: RAG hilft, „Halluzinationen“ (bei denen LLMs Fakten erfinden) zu verhindern, indem es Antworten auf überprüfbare, externe Daten stützt. Es ermöglicht LLMs, Quellen anzugeben, was das Vertrauen erhöht.
- Kosteneffizient & Effizient: RAG ist oft kostengünstiger als das Fine-Tuning eines gesamten Modells für neues Wissen. Es ruft nur relevante Informationen ab, wodurch die Anzahl der vom LLM verarbeiteten Tokens reduziert wird, was Kosten spart und schneller ist.
- Domänenanpassung: Ermöglicht LLMs, Fragen zu proprietären oder branchenspezifischen Daten zu beantworten, die nicht in ihrem ursprünglichen Training enthalten sind.
Das Kernproblem ist die Zustandslosigkeit und die begrenzten Kontextfenster von LLMs. RAG verändert die interne Architektur des LLM nicht grundlegend, sondern fungiert als
externes Gedächtnissystem. Dies stellt einen Paradigmenwechsel dar: Anstatt zu versuchen, das gesamte Wissen
in die Parameter des Modells zu stopfen (Fine-Tuning ), lehrt man das Modell,
wie es auf externes, dynamisches Wissen zugreifen kann. Dies ist ein entscheidender Schritt hin zu menschenähnlicheren kognitiven Architekturen, bei denen ein „Gehirn“ (LLM) mit einer „Bibliothek“ (Vektordatenbank) für den Langzeitabruf interagiert, wodurch LLMs effektiv ein „Langzeitgedächtnis“ erhalten. RAG bietet LLMs effektiv ein „Langzeitgedächtnis“ , indem es die Wissensspeicherung externalisiert. Dies ist eine praktische und skalierbare Lösung, die die Fallstricke vermeidet, neues Wissen direkt in die Modellparameter „einzustimmen“ , was zu einem „Überschreiben vorhandenen Wissens“ und „katastrophalen, unsichtbaren Schäden“ führen kann. RAG stellt einen robusteren und anpassungsfähigeren Ansatz zur Speicherverwaltung für reale Anwendungen dar.
Jenseits des Kontextfensters: Neue Speicherarchitekturen
Während RAG leistungsstark ist, wird weiterhin intensiv an der Entwicklung noch integrierterer und ausgefeilterer Speichersysteme für LLMs geforscht, die sich menschlicheren kognitiven Architekturen annähern.
Rekurrentes Gedächtnis
Inspiriert von rekurrenten neuronalen Netzen (RNNs) umfassen diese Mechanismen, die es dem Modell ermöglichen, relevante vergangene Informationen zu behalten und in zukünftigen Berechnungen wiederzuverwenden, ohne unbegrenztes Speicherwachstum. Dies kann „gated memory update mechanisms“ und „FIFO-style memory banks“ oder die Verarbeitung von Eingaben in „Chunks“ mit einem rekurrenten Speicherfluss zwischen ihnen umfassen. Das „Think-in-Memory“ (TiM)-Framework ist ein Beispiel dafür, bei dem LLMs „induktive Gedanken“ speichern und abrufen, anstatt nur rohe historische Daten. Dies zielt darauf ab, inkonsistente Schlussfolgerungen zu reduzieren und die Qualität der Antworten zu verbessern, indem das LLM Interaktionen „reflektiert“ und sein Gedächtnis mit verfeinerten Gedanken aktualisiert.
Speicherhierarchien
Inspiriert vom menschlichen Gedächtnis (Kurzzeit-, Langzeit-, Arbeitsgedächtnis) entwickeln Forscher mehrschichtige Speichersysteme. Dies beinhaltet die Optimierung der Datenspeicherung und des Datenzugriffs mit Techniken wie intelligentem Caching und hierarchischer Speicherverwaltung. Konzepte wie „MemOS“ charakterisieren das Gedächtnis entlang der Dimensionen implizit vs. explizit und zeitlicher Dauer (Kurzzeit- vs. Langzeitgedächtnis).
Kontextkompression
Diese Technik reduziert intelligent die Token-Anzahl des gesamten Prompts (einschließlich Anweisungen, abgerufener Kontext und Dialoghistorie), bevor er das LLM erreicht. Die Idee ist, redundante oder weniger informative Tokens zu identifizieren und zu entfernen, während die wesentliche Bedeutung erhalten bleibt. Methoden wie die „Recurrent Context Compression (RCC)“ können erhebliche Kompressionsraten (z.B. 32x) bei gleichbleibender Genauigkeit erzielen. Dies beinhaltet die Kodierung von Rohdaten in „virtuelle Speichertokens“, die den aktuellen Kontext zusammenfassen und Informationen über Fenster hinweg weitergeben.
Der Übergang von der bloßen Erweiterung der Kontextfenster zur Entwicklung von rekurrentem Gedächtnis, Speicherhierarchien und Kontextkompression bedeutet einen Schritt hin dazu, LLMs nicht nur „intelligenter“, sondern auch „kognitiv bewusster“ zu machen. Diese Fortschritte zielen darauf ab, menschliche Gedächtnisprozesse genauer nachzuahmen, was kontinuierliches Lernen, personalisierte Interaktionen und einen besseren Umgang mit komplexen, mehrstufigen Dialogen über sehr lange Zeiträume ermöglicht. Dies deutet auf eine Zukunft hin, in der KI-Agenten „Erfahrungen“ sammeln und sich während der Inferenz „entwickeln“ können, anstatt sich ausschließlich auf statische Trainingsdaten zu verlassen. Die Zukunft des LLM-Gedächtnisses geht nicht nur um größere Kontextfenster, sondern um den Aufbau ausgeklügelter „kognitiver Architekturen“ , die sich vom menschlichen Gedächtnis inspirieren lassen. Dazu gehören die Entwicklung von Systemen zur „Selbstevolution“ und „persistentem Wissen“ , die es LLMs ermöglichen, im Laufe der Zeit zu lernen und sich anzupassen, um über ihre derzeitige „zustandslose“ Natur hinaus zu wirklich intelligenten und personalisierten Assistenten zu werden.
RAG vs. Großes Kontextfenster: Ein Vergleich
Die Wahl zwischen einem großen Kontextfenster und RAG hängt stark vom Anwendungsfall ab. Beide Ansätze haben ihre Stärken und Schwächen, die man kennen sollte, um die KI optimal einzusetzen.
| Merkmal/Aspekt | Großes Kontextfenster (Long Context Window – LCW) | Retrieval-Augmented Generation (RAG) |
| Speichertyp | „Kurzzeitgedächtnis“ (Arbeitsspeicher) für die aktuelle Interaktion. | „Langzeitgedächtnis“ (externe Wissensbasis, z.B. Vektordatenbank). |
| Datenaktualität | Begrenzt auf Trainingsdaten-Cutoff + aktuelle Prompt-Inhalte. | Kann auf Echtzeitdaten zugreifen und diese integrieren. |
| Kosten | Quadratisch teuer mit zunehmender Länge. | Effizienter, da nur relevante Informationen verarbeitet werden. |
| Geschwindigkeit/Latenz | Langsamer bei sehr langen Kontexten. | Schneller, da weniger Tokens an das LLM gesendet werden. |
| Genauigkeit/Halluzinationen | Anfälliger für „Nadel im Heuhaufen“-Problem. Kann halluzinieren, wenn Kontext fehlt. | Reduziert Halluzinationen durch Faktengrundlage. |
| Implementierungsaufwand | Einfacher für den Endnutzer (nur längere Prompts). Für Entwickler: Skalierung schwierig. | Komplexer in der Einrichtung (Vektordatenbank, Chunking-Strategie etc.). |
| Debugging/Transparenz | Schwieriger zu debuggen bei Fehlern in langen Kontexten. | Leichter nachvollziehbar, da Quellen transparent sind. |
| Umgang mit irrelevanten Infos | Kann von irrelevanten Informationen abgelenkt werden („Needle in a Haystack“). | Ruft nur die relevantesten Informationen ab, filtert Rauschen. |
| Anwendungsfälle | Einfache, aber lange Textzusammenfassungen, Code-Analyse (wenn Kontext passt). | Anwendungen, die aktuelle, domänenspezifische oder proprietäre Daten benötigen (z.B. Kundenservice, Rechtsanalyse). |
| Komplementarität | Können sich ergänzen: Größere Kontextfenster können RAG-Systeme unterstützen, indem sie mehr abgerufene Informationen aufnehmen. |
Fazit: Dein smarter Umgang mit der „vergesslichen“ KI
Zusammenfassend lässt sich sagen, dass LLMs nicht wirklich im menschlichen Sinne „vergessen“; sie arbeiten innerhalb eines begrenzten „Kontextfensters“. Die Kontextfenstergrößen haben sich rasant entwickelt , aber es gibt auch inhärente Herausforderungen wie hohe Rechenkosten und das „Nadel im Heuhaufen“-Problem.
Als Nutzer hat man praktische Strategien (Prompt Engineering, Chunking), um die Gespräche effektiv zu gestalten. Die Bedeutung von entwicklerseitigen Lösungen wie RAG für ein echtes Langzeitgedächtnis und eine faktische Fundierung ist hervorzuheben. Zudem gibt es eine spannende, fortlaufende Forschung an fortschrittlicheren Speicherarchitekturen, die eine Zukunft noch kohärenterer und intelligenterer KI-Interaktionen versprechen.
Indem man diese zugrundeliegenden Mechanismen versteht, kann man effektiver mit KI interagieren und bessere Ergebnisse erzielen. Die „Vergesslichkeit“ ist kein Fehler, sondern ein Designmerkmal, mit dem man umgehen und arbeiten kann. Die Reise des KI-Gedächtnisses hat gerade erst begonnen, und man ist ein Teil davon!
Mehr in die Tiefe gehen?
Für diejenigen, die diese Thematik faszinierend finden und noch tiefer eintauchen möchten, gibt es einige spannende Forschungsbereiche:
- Transformer-Architektur und Self-Attention: Die Begrenzung des Kontextfensters ist eng mit der „Transformer-Architektur“ und ihrem „Self-Attention-Mechanismus“ verbunden. Dieser Mechanismus ermöglicht es dem Modell, die Wichtigkeit verschiedener Wörter in der Eingabe zu gewichten, aber seine Rechenkosten skalieren quadratisch mit der Sequenzlänge. Obwohl das Kontextfenster nicht „fest verdrahtet“ ist , ergeben sich praktische Grenzen aus den Positionskodierungen und der Länge der Trainingsdaten.
- Optimierungen für lange Kontexte: Es gibt fortlaufende Entwicklungen wie KV-Caching und verschiedene Positionskodierungsmethoden (wie RoPE ), die helfen, die Rechenlast längerer Kontexte zu bewältigen.
- Fortgeschrittene RAG-Techniken: RAG entwickelt sich ständig weiter mit „komplexen RAG-Setups“, die Abfrageumschreibung, Chunk-Neuanordnung und optimierte Vektorsuchen umfassen. Auch „Graph RAG“ verspricht eine verbesserte Abrufgenauigkeit.
- Forschung zu kognitiven Architekturen: Akademische Arbeiten befassen sich mit rekurrentem Gedächtnis (z.B. R3Mem ), Speicherhierarchien (MemOS ) und „Think-in-Memory“ für ein wirklich persistentes, menschenähnliches KI-Gedächtnis. Diese Ansätze zielen auf eine „KI-Selbstevolution“ ab.
- Das „Lost in the Middle“-Problem und seine Lösungen: Das „Nadel im Heuhaufen“-Problem wird weiter erforscht, und Techniken wie „Inference-Time Temperature Scaling“ oder „OP-RAG“ werden entwickelt, um die Erinnerungsleistung in sehr langen Kontexten zu verbessern.
Die detaillierten Forschungsfortschritte wie rekurrentes Gedächtnis, Speicherhierarchien und Kontextkompression sind nicht nur technische Optimierungen; sie stellen einen bewussten Versuch dar, LLMs über die einfache Mustererkennung hinaus zu komplexeren menschlichen kognitiven Funktionen wie Langzeitgedächtnis, Argumentation über riesiges Wissen und kontinuierliches Lernen zu führen. Dies deutet auf eine langfristige Vision in der KI-Entwicklung hin, in der Modelle nicht nur Werkzeuge, sondern zunehmend ausgeklügelte „Agenten“ sind, die Erfahrungen sammeln und sich entwickeln können. Die Zukunft des LLM-Gedächtnisses geht nicht nur um größere Kontextfenster, sondern um den Aufbau ausgeklügelter „kognitiver Architekturen“ , die sich vom menschlichen Gedächtnis inspirieren lassen. Dies beinhaltet die Entwicklung von Systemen zur „Selbstevolution“ und „persistentem Wissen“ , die es LLMs ermöglichen, im Laufe der Zeit zu lernen und sich anzupassen, um über ihre derzeitige „zustandslose“ Natur hinaus zu wirklich intelligenten und personalisierten Assistenten zu werden.



0 Kommentare